楽天、日本語に最適化した高性能LLM「Rakuten AI 7B」シリーズを公開! オープンソースコミュニティへ貢献し、AIのさらなる発展を加速
楽天は、日本語に最適化した高性能な大規模言語モデル(LLM)の基盤モデル「Rakuten AI 7B」と、同モデルを基にしたインストラクションチューニング済モデル「Rakuten AI 7B Instruct」、インストラクションチューニング済モデルを基にファインチューニングを行ったチャットモデル「Rakuten AI 7B Chat」をオープンなモデルとして公開した。
「Rakuten AI 7B」は、70億パラメータの日本語基盤モデルで、フランスのAIスタートアップであるMistral AI社のオープンモデル「Mistral-7B-v0.1」を基に、継続的に大規模なデータを学習させて開発された。事前学習には、楽天が設計した内製のマルチノードGPUクラスターを用いることで、大規模で複雑なデータを使用した事前学習プロセスを高速で実現。
本LLMは、日本語の言語に最適化された独自の形態素解析器を使用。一般的に形態素解析器は自然言語で書かれている文章を適切な単位に細分化して分析することができる。楽天の形態素解析器においては、文章の分割単位であるトークンあたりの文字数が増加し、その結果、より多くの情報を単一のトークンに含めることが可能。そのため、従来の形態素解析器と比較して、事前学習や推論のテキスト処理をより効率的に行えるようになった。
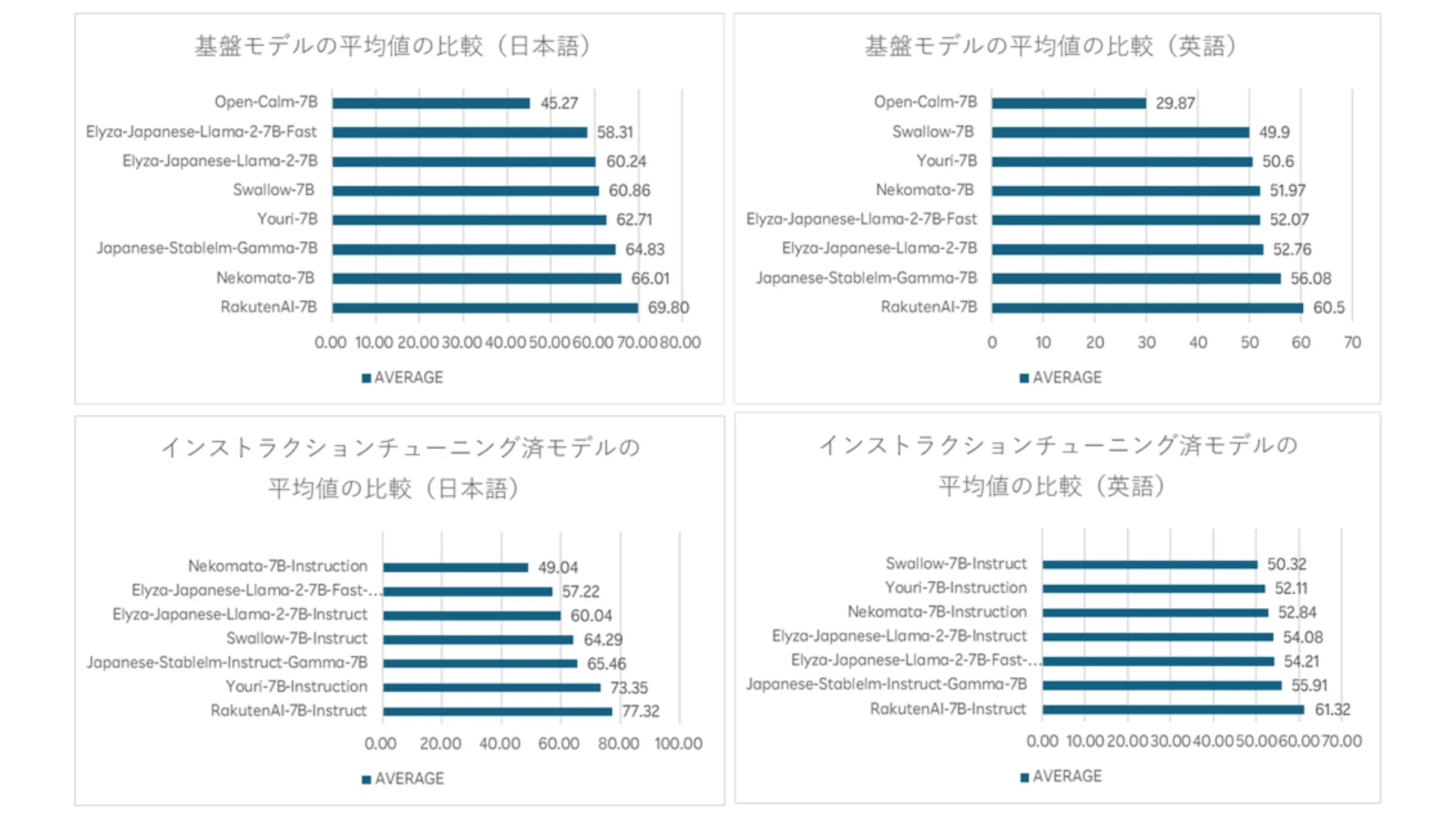
本基盤モデルと本インストラクションチューニング済モデルは、言語モデル評価ツール「LM Evaluation Harness」の基準において、日本語と英語のLLMの高いパフォーマンスが評価され、高性能であることが実証された。日本語の評価では、本基盤モデルが平均69.8ポイント、本インストラクションチューニング済モデルが平均77.3ポイントのスコアを獲得、英語の評価では、本基盤モデルが平均60.5ポイント、本インストラクションチューニング済モデルが平均61.3ポイントのスコアを獲得し、オープンな日本語LLMにおいて、大変優れたモデルとなっている。
3モデルは、文章の要約や質問応答、一般的な文章の理解、対話システムの構築など、様々なテキスト生成タスクにおいて商用目的で使用することができるほか、本基盤モデルは他のモデルの基盤としても利用可能。
楽天CDOのティン・ツァイ氏は、楽天のLLMに関して次のようにコメントしている。
「楽天は、お客様の課題を解決するためにテクノロジーを駆使して最適なツールを活用したいと考えています。楽天は、多様なAIモデルや、長年にわたって独自に開発を続けてきたデータサイエンス、機械学習モデルなど、幅広いポートフォリオを保有しています。そのため、コストや品質、性能の面で様々な顧客ニーズを解決するための最適なツールが提供可能です。このたび、大規模な日本語の言語基盤モデル『Rakuten AI 7B』の開発を通じて、楽天が得た知見をオープンソースコミュニティと共有し、日本語LLMのさらなる開発と発展に貢献できることを楽しみにしています」
LLMは、昨今のAI革命を引き起こした生成AIを支える中核のテクノロジー。楽天は、現在のLLMを研究目的で開発しており、お客様に最高のサービスを提供するため、今後も様々な選択肢を評価検討していく。また、社内においてモデル開発することで、LLMの知識と専門性を高め、楽天エコシステムをサポートするための最適化されたモデル作成を目指していく。さらに、楽天はオープンソースコミュニティへの貢献を目指し、本LLMをオープンなモデルとして提供することで、国内外におけるAIのさらなる発展を後押ししていく。
楽天は、AI化を意味する造語「AI-nization(エーアイナイゼーション)」をテーマに掲げ、さらなる成長に向けてビジネスのあらゆる面でAIの活用を推進する取り組みをしている。今後も豊富なデータと最先端のAI技術の活用を通じて、世界中の人々へ新たな価値創出を目指していく。