東京大学松尾研究室発のELYZA、商用利用可能な70億パラメータの日本語LLMを一般公開

言語生成AIの社会実装を進める東京大学松尾研究室発・AIスタートアップの株式会社ELYZAは、Meta Metaが開発したLLM(大規模言語モデル)である「Llama 2」に対し日本語による追加事前学習を行ない、商用利用可能な70億パラメータの日本語LLM「ELYZA-japanese-Llama-2-7b」を開発し、一般公開した。
Llama 2とは、2023年7月18日にMeta社が公開した英語ベースの大規模言語モデルで、先に公開された「LLaMA」が研究用途に限定されていたのに対し、Llama 2は商用利用も可能となっている。公開されているモデルとしてはとても性能が高いことから、OpenAIのGPT-4やGoogleのPaLMなどのクローズドなLLMと競合する形で、英語圏では既にオープンモデルのデファクトスタンダードとなりつつある。
サイズは70億、130億、700億の3種類となっており、いずれのモデルも教師ありファインチューニング(Supervised Fine-Tuning、SFT)及び、人間からのフィードバックに基づいた強化学習(Reinforcement Learning from Human Feedback、RLHF)を施したchatモデルも同時に公開された。
「ELYZA-japanese-Llama-2-7b」はMetaの「Llama-2-7b-chat」に対して、約180億トークンの日本語テキストで追加事前学習を行ったモデルで、学習に用いたのは、OSCARやWikipedia等に含まれる綺麗な日本語テキストデータになっている。その他、ELYZAでは、独自の事後学習を施した「ELYZA-japanese-Llama-2-7b-instruct」や、日本語の語彙追加により高速化を行った「ELYZA-japanese-Llama-2-7b-fast-instruct」といったモデルも公開している。
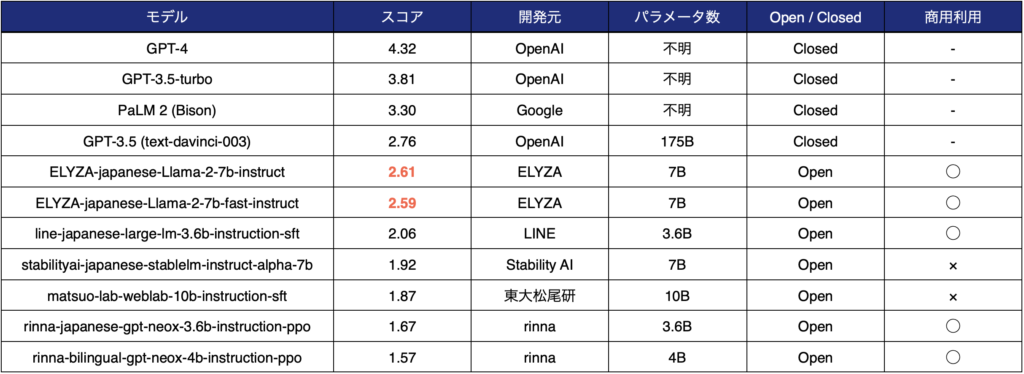
70億のパラメータ数は、公開されている日本語のLLMとしては最大級の規模。
また、ライセンスはLLAMA 2 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能だ。

性能について、ELYZA独自作成の性能評価の結果、1750億パラメータを有する「GPT-3.5 (text-davinci-003)」に匹敵するスコアが算出されており、日本語の公開モデルのなかでは最高水準の性能。
ELYZAではLlama 2の130億、700億パラメータのモデルの日本語化にも既に着手してとのことで、近いうちによりパワーアップしたモデルを届けられるよう、開発を進めていくとのこと。さらにLlama 2での取り組みに限らず、海外のオープンなモデルの日本語化や、自社独自の大規模言語モデルの開発に継続して投資をしていくとのことなので、今後のELYZAの動向には目が離せない。
■関連サイト
ニュースリリース(技術ブログ)
ELYZA-japanese-Llama-2-7b-instructデモ
ELYZA Tasks 100
ELYZA